This blog post is the first in a series of articles on performance engineering (PE) research I did some time ago. I touched the topic of PE a bit in one of previous blog articles. This time it’ll be purely practical.
The picture was generated by Nano Banana and contains pretty obvious errors. I decided to keep it still as it’s pretty hilarious.
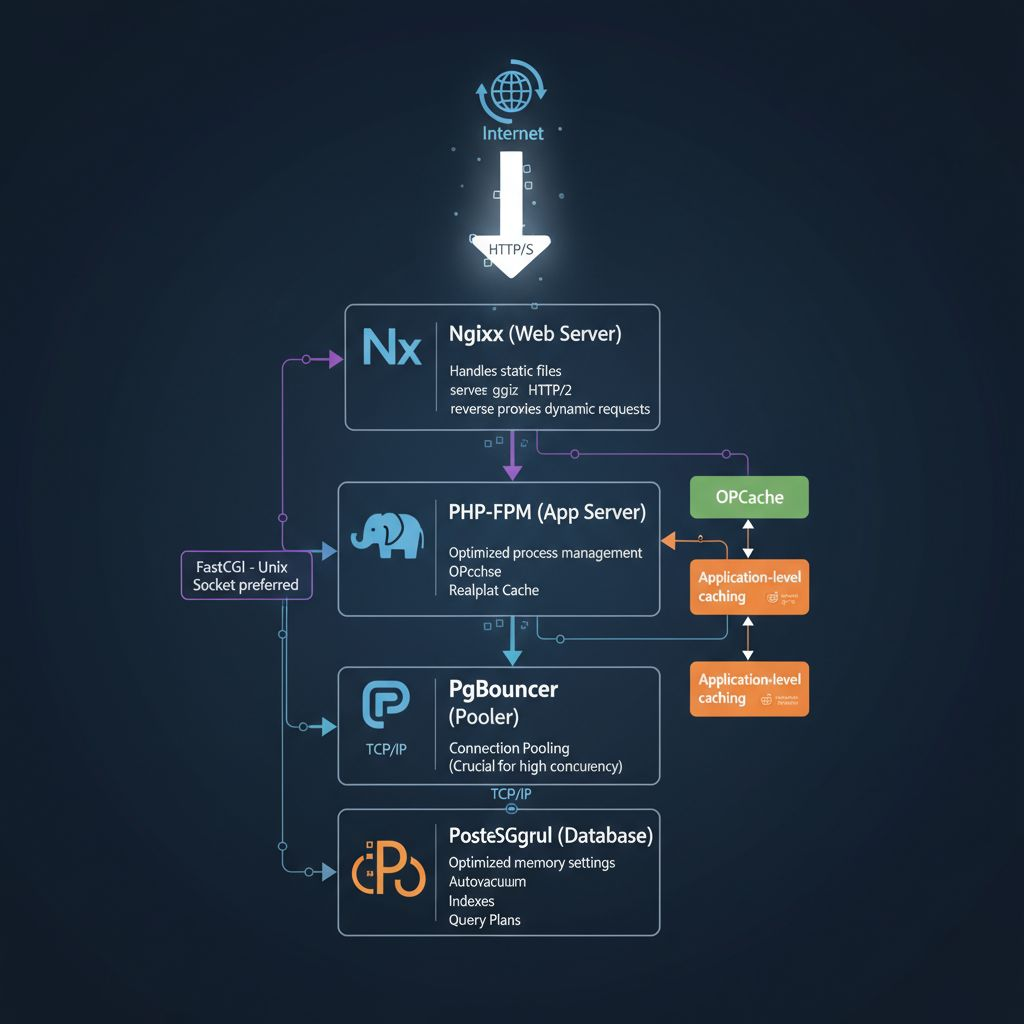
Setup for Max Performance of Nginx, PHP & PostgreSQL Chain Research
I wanted to find out performance limits of a particular request processing pipeline. It starts from Nginx which acts as a reverse proxy. Proxy forwards requests to another Nginx and PHP-FPM which talk to each other via Unix socket. That second piece will be “backend”. Finally there’s a PostgreSQL aka “db” where PHP-FPM may send requests.
I looked at performance of the following use cases:
- Serving purely static HTML hosted by the backend (no PHP executed)
- Serving simple PHP page with a bit of code but no DB access
- Serving PHP page which involves querying the DB
The software setup was super easy – just one Docker Compose file with three containers:
services:
frontend:
image: nginx:1.23.3
ports:
- "8080:80"
...
backend:
image: richarvey/nginx-php-fpm:3.1.6
...
postgresql:
image: postgres:14.1
...Hardware was very modest – a laptop with Intel Core i7-7700HQ CPU @ 2.80GHz. Such CPU contains 4 HT cores on a single socket yielding 8 logical threads. There was plenty of RAM – 32 GB.
The method was as follows:
- Apply increasing request rate via K6
- Find breaking point in RPS
- Find out what can be done to increase max RPS
- Start over
Static Content at 5k RPS
So the first step was to make request rate ramp up in 1 minute up to 5k. I pre-allocated 1k VUs just in case but it turned out to be unnecessary. The dynamic was always simple:
- Up to the breaking point (around 2k RPS the last time I tested) up to 10 VUs is enough since request serving latency is minimal
- After the breaking point all 1k VUs quickly become busy as request serving latency skyrockets
Proxy CPU usage jumps up to 600% (i.e. 6 out of 8 logical cores) after the breaking point. WTF is going on? Let’s sample CPU and find out!
sudo perf record -e cycles:ppp -F 99 -g --cgroup system.slice/docker-%proxy_container_id%.scope
sudo perf script report flamegraph
400 / 5400 on-CPU samples before / after breaking up. After the breakup tcp_v4_connect is present in 93% of samples, before – only in 14%. Samples with __inet_hash_connect jump up from 1% to 78%.
Kernel source isn’t the most straightforward but after a while I arrived at a hypothesis. Looking up a free local port to establish a new TCP connection involves spinlocks. When local port range is exhausted Nginx gets busy spinning CPU while it awaits for a port to free up.
Digging for Closed Sockets in Max Performance of Nginx, PHP & PostgreSQL Chain
We can prove that correct by the following:
docker inspect -f '{{.State.Pid}}' %frontend_container_id%
sudo watch -n 1 nsenter -t %frontend_container_pid% -n ss -s
And watch how Nginx runs amok as soon as established + time wait + closed sockets number gets up to 30k. 30k is derived from net.ipv4.ip_local_port_range kernel setting which is 32768-60999 by default, i.e. less than 30k ports available.
It’s counter-intuitive why closed sockets count against the outgoing port range limit. There are some non-trivial kernel mechanics involved in TCP stack machinery. So it seems that really free socket is no socket =)
By adding sysctl block to proxy container with net.ipv4.ip_local_port_range=1024 65535 we can increase max RPS. We can’t just change these settings on the host since these are namespaced kernel params. The last time I tested that yielded 3k RPS.
However, there’s a better way – just reuse connections on proxy side! Adding these to the backend location block in the proxy config:
proxy_http_version 1.1;
proxy_set_header Connection "";
Plus adding keepalive 2; to upstream block instead of sysctl block in Docker Compose file allows passing 5k mark without issue. Just 8 VUs max were used the last time I tested. ss -s also confirms sockets number is in check.
Why 2 ? At some point I found it’s somehow related to CPU cores available but that’s not correct. Let’s find out why.
Static Content at 15k RPS
When 5k was beaten I tried to make request rate ramp up in 1 minute up to 15k. VUs setup was the same and bearing in mind 5k results keep alive was set up. It started to break up around 11k RPS and the dynamic was similar to the non-persistent connections for 5k:
- Up to the breaking average VUs usage is close to 1 with occasional spikes since request serving latency is minimal
- After the breaking point all 1k VUs quickly become busy as request serving latency skyrockets
The symptoms were all the same as without persistent connections at 5k – high CPU usage by Nginx, many closed + timewait sockets etc. After some research I found many interesting Nginx config params like keepalive_requests, keepalive_time and keepalive_timeout (check the docs if interested).
The main thing was that when number of keepalive connections is low then Nginx uses regular connections when it needs more of them. These connections get closed. That explained closed + timewait sockets accruing. Since there was no more than 1k VUs anyway I just changed it to keepalive 1024; (not simply 1k just for the sake of power of 2).
That did the trick and 15k RPS was beaten. There were some short bursts up to 1k VUs but latency never went off rails. So did the resource usage.
I decided that’s enough of squeezing from my box for that scenario. So I switched to ones involving PHP & database.
Conclusion
Next time we’ll look at full chain performance including DB access. Stay tuned!